スキャナーで撮った資料やネットからダウンロードした画像やPDFを自分用の資料として文字起こし(OCR)しようと思っていた矢先、ソースネクストから「読取革命V16」がセール(6,980円 (標準価格 12,980円 割引率 46%)かつクーポンで1,000円引き)があったので、ちょっと衝動買いしてしまいました。
今まではDocuworks7.3でOCRしていました
本来は業務用なんですが、個人の書類管理にもちょうど良いのでDocuworks7.3のOCR機能を使っていました。OCRとしては高性能ではありませんが、ちょっとした文字認識なら十分だったのですがDocuworks7.3で読み切れない資料が出てきたため、読取革命V16を購入してみました。
起動画面はこんな感じ
使い方は簡単
PDFやJpgファイルをドラッグ&ドロップすれば自動的に読込が始まって、OCR変換先を指定(Word、ppt,excel、テキスト)すればOK
変換結果
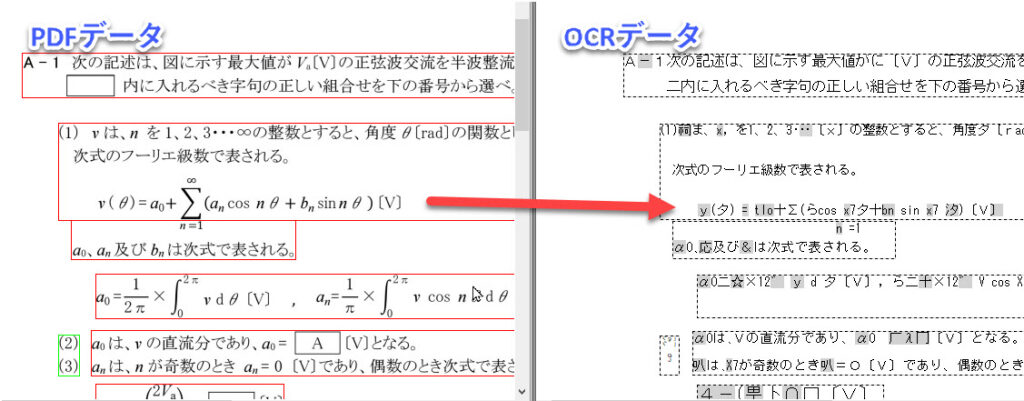
例)試験問題
試験問題の虫食い部分や数式、∞(無限大)等の検出は非常に難しいらしく、OCRデータだけ見ると何が書いてあるのかが読めないです。